Credit scoring tells you the risk of a borrower. Credit decisioning tells you what to do about it.
Scoring outputs a number, usually 300 to 850, or a probability of default. Decisioning outputs an approve, a manual review, or a reject, plus an auditable reason.
Lenders need both. They are not the same product, sold by the same vendor, to the same buyer. The lenders that confuse the two pay for it twice: once by buying the wrong thing, then again rebuilding when an auditor asks why a loan was rejected.
This guide explains the difference, why it matters in 2026, and how to architect a stack that uses both correctly.
Quick comparison
| Credit scoring | Credit decisioning | |
|---|---|---|
| What it produces | A number (e.g. 720) or probability (e.g. 0.04) | A decision: approve, manual review, or reject |
| Primary input | Bureau data, alt-data signals, applicant history | Score + bureau + documents + KYC + your policy |
| Who buys it | Data science, model risk, analytics | Credit and risk teams, Head of Credit, Chief Risk Officer, credit ops |
| Main vendors | FICO Score, VantageScore, Zest AI, CredoLab, Trusting Social | Floowed, Taktile, Provenir, GDS Link, FICO Platform |
| Configurable by you | Lightly (you can re-train) | Heavily (you encode your policy) |
| Failure mode | The number is wrong | The outcome is wrong (loan lost, fraud through, audit fail) |
| Audit answer | "Why this score?" | "Why this decision?" |
| Pricing model | Per-pull or licensed model | Consumption-based on credits, sized to your operation on one short call |
What is credit scoring?
Credit scoring is a statistical or machine-learning model that produces a number representing how likely a borrower is to default. The number itself approves no one and rejects no one. It just sits there as an input.
The most familiar examples are bureau scores: FICO Score in the US, VantageScore, the Experian Delphi suite, CIBIL in India, and local-bureau scores in markets worldwide. These ride on top of formal credit history.
Newer AI credit scoring vendors have built models for thin-file or new-to-credit borrowers, where a bureau score either does not exist or is unreliable:
- Zest AI builds custom ML models trained on a lender's own portfolio plus thousands of additional data points, on top of US bureau data.
- CredoLab produces a behavioural score from smartphone metadata (typing speed, app ownership, device age) for thin-file applicants across emerging markets.
- Trusting Social builds a Trust Score from telco, social, and digital data for thin-file borrowers.
Whoever provides the score, the output is the same shape: a number, a probability, sometimes a confidence band. Nothing happens to a loan application because a score arrived. Something happens because a decision was made on top of it.
What is credit decisioning?
Credit decisioning is the layer above scoring. It takes the score, plus everything else that matters (bureau data, KYC, document intelligence on payslips and bank statements, fraud signals, your own credit policy) and produces a decision: approve, route to manual review, or reject. It also produces a reason that an auditor can understand.
Credit decisioning vendors include the modern wave (Taktile, Provenir, GDS Link, Scienaptic, Lentra) and the incumbents (FICO Platform, Experian PowerCurve, CRIF Strategy One). They differ in product depth, pricing, deployment time, and how much engineering you need to operate them. They share the same shape: they decide, they don't score.
Floowed is a credit decisioning platform. We do not produce a score. We orchestrate any score you trust (FICO, Zest, CredoLab, your in-house model) into a decision your credit and risk teams and your regulator can defend.

Five differences that actually matter
1. Output shape
A score is a number. A decision is a verb. You can't act on a number until you've wrapped policy around it. "720" doesn't tell you whether to approve. "Approve at 18% APR with a 24-month term, because the applicant scored 720, has six months of clean bank statements, and falls inside our approved SME segment" is the decision. Decisioning is what produces that sentence.
2. Input breadth
Scoring usually consumes a narrow input set: bureau data, payment history, alt-data features. The model is trained, validated, deployed, then it scores.
Decisioning consumes a much wider set: the score itself, bureau pulls, KYC checks, document intelligence on payslips and ID cards and bank statements, fraud signals, internal blacklists, and your written credit policy. Decisioning is where data orchestration happens.
3. Configurability
A score is mostly fixed once deployed. You can re-train it quarterly, you can switch model versions, you can A/B test, but you don't typically adjust the score for a specific applicant.
Decisioning is where your business judgment lives. "We don't lend to this industry above this exposure." "We need two months of bank statements for SME loans, four for commercial." "If the score is borderline but the applicant is a returning customer with clean history, send it to manual review with a senior officer." That is policy. Policy is the lender's intellectual property. A good decisioning platform lets a credit officer change policy without filing an engineering ticket.
4. Buyer
Scoring is bought by data science, model risk, and analytics teams. The questions are about model performance, AUC, KS, monotonicity, fairness, regulatory model documentation.
Decisioning is bought by the credit and risk teams: the Head of Credit, the Chief Risk Officer, sometimes the COO. The questions are about decision velocity, audit defensibility, override workflows, exception handling, and how fast a credit officer can change a rule when conditions change.
These are different buyers in the same company, with different budgets and different procurement cycles. Selling a decisioning platform to a data science team usually fails. Selling a scoring model to a credit officer usually fails. The lenders that succeed match the right product to the right buyer.
5. Failure mode
When scoring fails, you get the wrong number. The lender either approves a borrower who defaults or rejects a borrower who would have paid. The cost is real but contained. The fix is model retraining.
When decisioning fails, you get the wrong outcome. Approvals you didn't authorise. Rejections you can't explain to an auditor. Fraud through the front door because a policy node didn't fire. Loans on terms outside your risk appetite because a workflow misrouted a manual review. The cost compounds across every application that hits the broken decision path.
Why this distinction matters in 2026
Three forces have made the scoring/decisioning split commercially urgent.
Regulators want to see decisions, not scores. Regulators across major lending markets have all moved toward "explain the decision" expectations. A scoring model can't tell an auditor why this specific applicant was rejected while that one was approved. A decisioning platform can. Lenders that bought a scoring model and called it "our underwriting AI" are discovering they don't have the artefact regulators are now asking for.
Loan book growth without proportional risk growth is the universal mandate. The fastest path is automating decisions on the safe middle of the distribution so that human credit officers spend their time on the borderline cases that need judgment. That requires decisioning. Better scoring helps at the margin, but you can't auto-approve a loan with just a score.
Enforcement has become the differentiator. A credit policy that lives in a manual or a spreadsheet gets applied as many ways as there are credit officers reading it. A decisioning platform enforces it: the policy you write is the policy that runs, identically, on every application, with version history and a decision record to prove it. As more of the decision path is automated, the question buyers ask has shifted from "how accurate is the model?" to "can I prove the policy ran the same way on every application?"
How scoring and decisioning work together
A modern lending stack looks roughly like this:
- Application intake. Web form, broker portal, branch counter, mobile app.
- Identity and KYC. Document checks, biometric verification, sanctions screen.
- Document intelligence. This is where Floowed reads and analyses payslips, bank statements, IDs, and business registrations into decision-ready data: income normalization, cash-flow and bank-statement analysis (ADB, DSCR), fraud and tampering signals, cross-document validation. Floowed's native handling of handwritten, scanned, and photographed input matters in markets where applicants don't deliver clean PDFs. It reads and analyses the paperwork other IDPs (Ocrolus, Rossum, Hyperscience) choke on.
- Bureau pulls. Local and international bureaus (Experian, TransUnion, Equifax, and regional bureau subsidiaries).
- Score generation. Bureau score for thick files. Alt-data score (CredoLab, Trusting Social, an in-house model, or a Zest-style custom ML model) for thin files.
- Decisioning. Take all of the above, run it through the policy: approve, manual review, reject, plus rate, term, conditions. Log the reason. Notify the applicant. Push the loan into the LMS.
- Loan management and servicing. Disbursal, collections, performance tracking. Performance data flows back into both scoring (for retraining) and decisioning (for policy iteration).
Steps 5 and 6 are the scoring and decisioning layers. They are different products, often sold by different vendors, and they integrate via API. Floowed lives at step 6, and accepts inputs from any score at step 5. We are score-agnostic by design: bring any score or your own model, and we absorb it unchanged. That's the point.

When you need each
| If you need… | You need… |
|---|---|
| A model that predicts default risk on thin-file applicants | A scoring engine (CredoLab, Trusting Social, custom ML) |
| To approve or reject 80% of applications automatically | A decisioning platform |
| To replace your bureau score | A scoring engine |
| To change credit policy with the impact known before it goes live | A decisioning platform with back-testing |
| An audit trail showing why a specific loan was rejected | A decisioning platform |
| To grow your loan book without growing your underwriting headcount | A decisioning platform first, scoring as input |
| To unify origination, KYC, document intelligence, and policy into one decision | A decisioning platform |
| A black-box score that lifts AUC by 5% | A scoring engine |
If you only have one of the two, you're either making decisions you can't explain (scoring without decisioning) or making slow, manual decisions on top of a good number (decisioning without a useful score). The lenders that scale cleanly tend to have both, configured to talk to each other.
Common mistakes
1. Buying a score and expecting it to make the decision. The most expensive mistake. The score arrives, nothing happens, the credit officer still copy-pastes data into a spreadsheet. Six months later the lender writes a procurement RFP for a "decisioning platform" without realising that's what they should have bought first.
2. Buying a decisioning platform and expecting it to predict default better than your bureau score. Decisioning platforms ride on top of scores; they don't replace them. If you have a weak score input, decisioning won't fix it. Improve the score input first.
3. Treating "AI underwriting" as one product. Vendors selling either layer happily call themselves "AI underwriting." The phrase obscures the layer they actually operate on. Always ask: do you produce a number, or do you produce a decision?
4. Locking into one bureau or one score vendor. Some decisioning platforms assume you'll use a particular bureau lineage. That works until you expand into a new market with a different bureau, or until you want to ensemble scores from multiple sources. Score-agnostic decisioning is more flexible by default.
5. Optimising for model accuracy without optimising for decision velocity. A score that is 2% more accurate but takes a week longer to integrate often costs more in lost approval-time than it earns in reduced default rate. Total decision time matters, not just model AUC.
Floowed's POV
Floowed is decisioning, not scoring. We do not compete on score quality. We compete on decision quality.
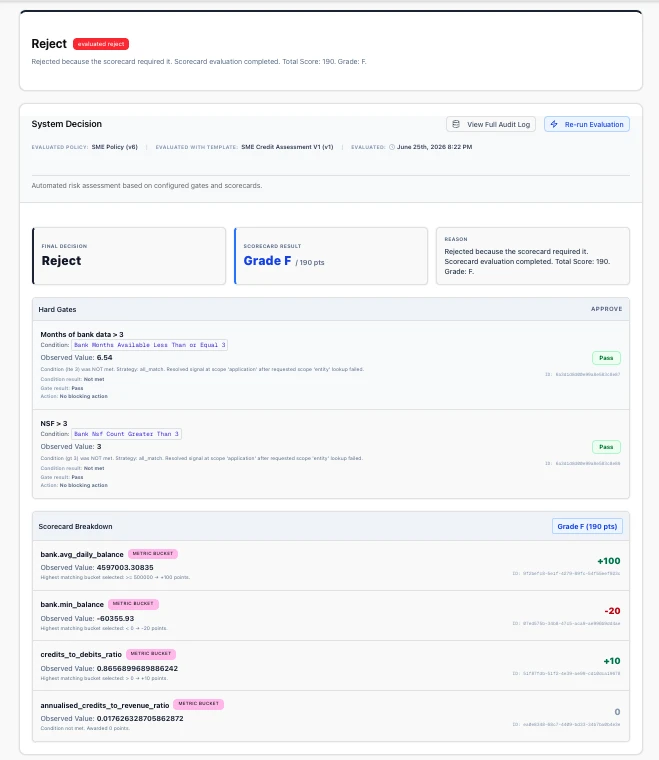
The Decision Engine is our policy builder. A policy is a scorecard plus separate hard gates, owned and versioned by your credit and risk teams. Every change is back-tested: replay it against your historical book and its real outcomes before it runs, so the approval-rate and NPL impact are known, not guessed. Every decision logs the policy path it followed, so an auditor can answer "why this outcome?" without a discovery exercise. The policy you write is the policy that runs. Same policy. Every application. Every time. No exceptions.
We orchestrate any score input you trust (bureau scores, Zest, CredoLab, Trusting Social, your in-house model) alongside native document intelligence that reads and analyses handwritten and photographed bank statements, payslips, and IDs end-to-end (income normalization, cash-flow analysis, fraud signals, cross-document validation), which matters in markets where applicants don't deliver clean PDFs, plus KYC, fraud signals, and your written credit policy.
This is already in production. At Alon Capital, founder Rene de Jesus puts it plainly: "Floowed reads the documents, runs our credit policy, and surfaces a decision in minutes."
Floowed pricing is consumption-based on credits, sized to your operation on one short call, not a months-long sales cycle, and it lands well under the large enterprise platforms with their long, complicated procurement. There is no procurement RFP and no professional services minimum. Proper configuration takes weeks, not the quarters the enterprise platforms force on you, and what goes live at the end of it is your policy, running exactly as written.
FAQ
Is credit decisioning the same as a loan origination system (LOS)?
No. An LOS handles the full lifecycle from application intake through disbursal and ongoing servicing. A decisioning platform handles the credit decision specifically and integrates with your LOS via API. Most modern LOS platforms (nCino, MeridianLink, Mambu, Cloudbankin) expect a decisioning platform alongside them, not bundled in.
Can credit scoring replace credit decisioning?
No. A score is one input to a decision. Replacing decisioning with just a score is like replacing a thermostat with a thermometer: you can read the temperature but the room never adjusts.
How do you change a live credit policy safely?
Version it and back-test it. In Floowed, a proposed policy change is replayed against your historical loan book and its real outcomes before it goes live, so the approval-rate and portfolio impact are known up front instead of discovered in production. Versioning, audit trail, and rollback come standard with the Decision Engine.
Do I need both a scoring vendor and a decisioning platform?
Almost always yes, although one of the two might be in-house. Many lenders use bureau scores plus their own scoring model on top, then a decisioning platform to operationalise the result. A small number of lenders use only their bureau score plus a decisioning platform, with no custom model. Very few use only a scoring model with no decisioning layer, and those usually regret it once they scale.
How does credit decisioning handle regulatory audits?
A good decisioning platform logs the policy path each application traversed: which inputs the decision used, which rules fired, what the outcome was, and which version of the policy was active at decision time. When an auditor asks "why was this loan rejected in March?", you reproduce the exact decision path. Scoring alone can't do this.
Can decisioning platforms approve loans automatically?
Yes, that's the central use case. Most lenders auto-approve the safe middle of the distribution (typically 60-80% of applications), auto-reject a much smaller tail, and route the borderline middle to manual review. The decisioning platform sends each review to the right credit officer with the right context.
What about agentic AI: is decisioning being replaced by AI agents?
Decisioning is being expressed through AI agents, not replaced by them. Agentic features in decisioning platforms make the underlying decisioning system easier to operate. The audit trail and the policy structure remain. The agent is a UI on top.
How does Floowed compare to Taktile, Provenir, FICO Platform?
We're closer to Taktile in product philosophy (modern, fast to deploy, policy owned by credit and risk teams). We're dramatically cheaper than FICO Platform, Provenir, and CRIF Strategy One, and faster to deploy than any of them. Where Floowed pulls ahead of all of them is native document intelligence: we read and analyse the messy, real-world loan paperwork (handwritten, scanned, photographed) that US-built IDPs choke on. Detailed comparisons live at /insights/floowed-vs-taktile, /insights/floowed-vs-provenir, and /insights/floowed-vs-zest-ai.
Book a demo
See the Decision Engine in motion. We'll show you how a credit officer encodes your policy, how scores from any source plug in as inputs, and how every decision produces an audit trail your regulator can read.